آمار و احتمال قابلیت اطمینان
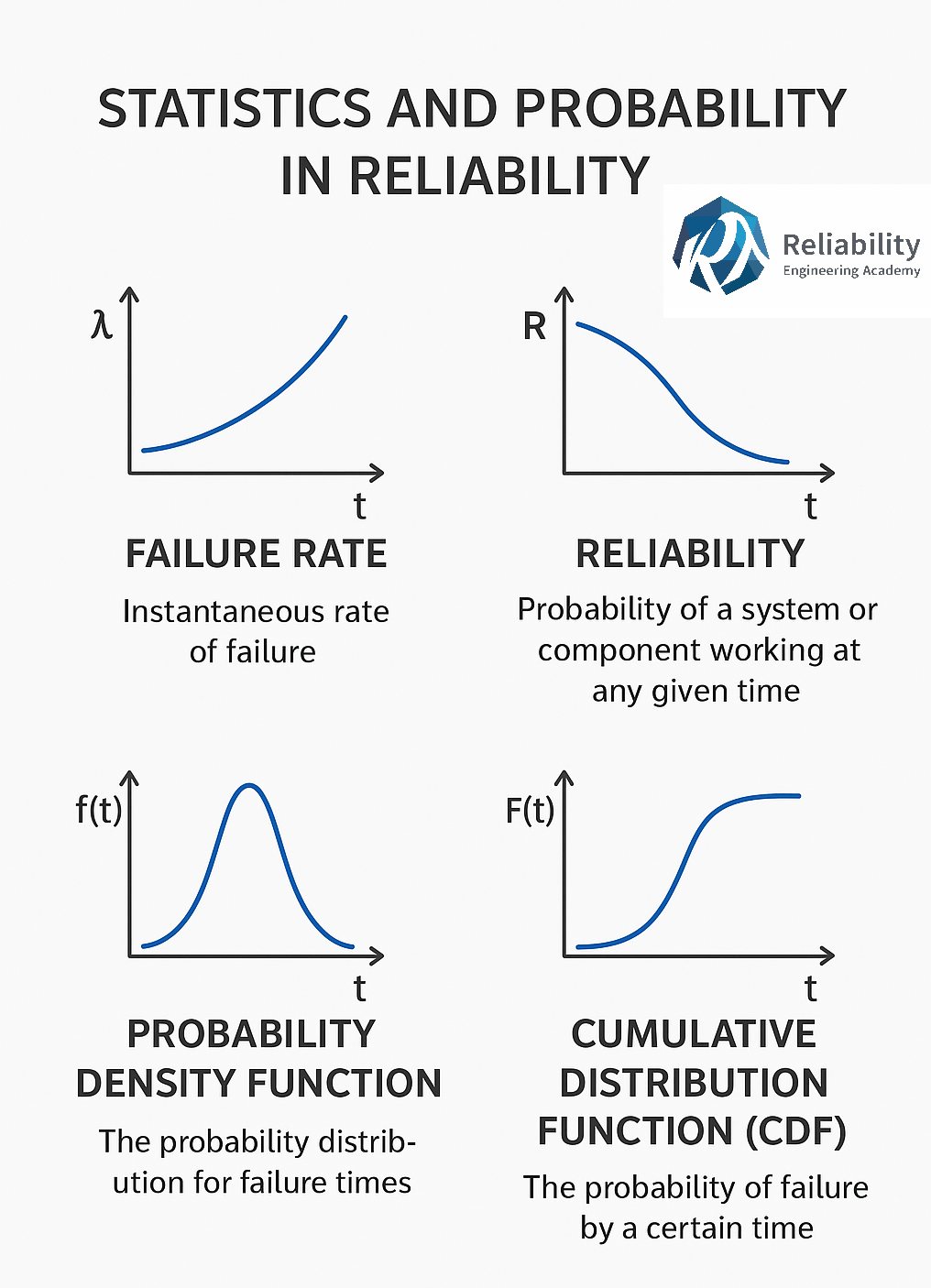
آمار و احتمالات مهندسی قابلیت اطمینان
مقدمه
احتمال با پیشبینی احتمال رویدادهای آینده سروکار دارد، در حالی که آمار شامل تحلیل فراوانی رویدادهای گذشته است. احتمال در درجه اول یک شاخه نظری از ریاضیات است که پیامدهای تعاریف ریاضی را مطالعه می کند. آمار یک شاخه کاربردی از ریاضیات است که سعی می کند مشاهدات را در دنیای واقعی معنا کند.
 جامعه آماری: یک جامعه آماری را میتوان با شاخصهای مرکزی میانگین و واریانس (انحراف معیار) توصیف کرد.
جامعه آماری: یک جامعه آماری را میتوان با شاخصهای مرکزی میانگین و واریانس (انحراف معیار) توصیف کرد.
نمونه آماری: به دلایل متعدد (هزینه، زمان و تغییر ویژگی جامعه در طول زمان) جامعه آماری را نمی توان به سادگی اندازه گیری و توصیف کرد. بنابراین باید به سراغ نمونه آماری رفت.
قضیه احتمال کل
زمانی که از قبل وقوع یک پیشامد تصادفی را بدانیم، به کمک فرمولهای احتمال شرطی میتوانیم مقدار احتمال برای هر پیشامد دیگر را محاسبه کنیم. طبق فرمول احتمال شرطی با در نظر گرفتن اینکه P(B)>0 (یعنی پیشامد B یک پیشامد محال نباشد)، داریم:
P(A|B)=(P(A∩B))/(P(B))
حال اگر فضای نمونه براساس رخداد یا عدم رخداد پیشامد B تفکیک شود، برای بدست آوردن احتمال A میتوانیم دو حالت در نظر بگیریم: یا پیشامد B رخداده، یا رخ نداده است. با این کار فضای نمونه را به B و B′ افراز کردهایم (منظور از B′ مکمل پیشامد B است).
محاسبه احتمال براساس افراز
منظور از افراز یک پیشامد مثل B، ایجاد زیرمجموعههای مثل B1، B2 و … Bn است به طوری که این پیشامدها دو به دو ناسازگار باشند و اجتماع آنها مجموعه B را بسازد. این موضوع را به زبان ریاضی به صورت زیر مینویسیم:
Bi∩Bj=∅,i≠j
B=∪_(i=1)^n B_i
و در این حالت میگوییم، Biها یک افراز روی B ایجاد میکنند.
با توجه به این تعریف فرض کنید که B و B′ یک افراز رویS باشند. در این صورت احتمال پیشامد A را میتوانیم به صورت زیر بنویسیم:
P(A)=P(A∩S)=P(A∩(B∪B’)=P(A∩B)+P(A∩B’)
با توجه به قانون ضرب احتمال خواهیم داشت:
P(A)=P(A|B)P(B)+P(A|B’)P(B’)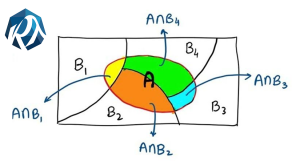 و در حالت کلیتر اگر افراز را ظریفتر کنیم، به صورتی که B1,B2,…,Bn یک افراز روی S باشند، آنگاه احتمال پیشامد A به صورت زیر محاسبه میشود:
و در حالت کلیتر اگر افراز را ظریفتر کنیم، به صورتی که B1,B2,…,Bn یک افراز روی S باشند، آنگاه احتمال پیشامد A به صورت زیر محاسبه میشود:
P(A)=∑〖P(A|Bi)P(Bi)〗
که به این رابطه، قضیه یا فرمول احتمال کل گفته میشود.
P-Value چیست؟
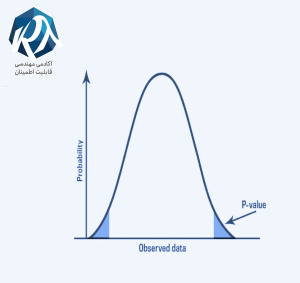
P-value به زبان ساده نشان میدهد که اگر فرض صفر () درست باشد، احتمال مشاهده دادههایی که مساوی یا بیشتر از دادههای فعلی، غیرعادی هستند، چقدر است.
به بیان دیگر:
- اگر -value کوچک باشد (مثلاً کمتر از 0.05)، به این معناست که مشاهده دادهها تحت فرض صفر خیلی غیرعادی است.
- اگر -value بزرگ باشد (مثلاً بیشتر از 0.05)، به این معناست که دادهها تحت فرض صفر منطقی و عادی هستند.
ارتباط P-value با آلفا (α)
آلفا سطح معناداری (Significance Level) است که شما از پیش تعیین میکنید (مثلاً 0.05 یا 5%). این مقدار مشخص میکند که چقدر آمادهاید تا یک خطای نوع اول (رد کردن اشتباه فرض صفر) را بپذیرید.
ارتباط:
- اگر -value کمتر از آلفا باشد (-value < α): فرض صفر را رد میکنیم (دادهها نشان میدهند که فرض صفر نادرست است).
- اگر -value بزرگتر یا مساوی آلفا باشد (-value ≥ α): فرض صفر را رد نمیکنیم (دادهها به اندازه کافی شواهد برای رد فرض صفر ندارند).
محاسبه P-value
برای محاسبه P-value، ابتدا باید یک آزمون آماری مناسب انتخاب کنید و سپس مراحل زیر را طی کنید:
1. تعریف فرضیات آماری
- فرض صفر (): بیانگر وضعیتی است که میخواهیم آن را تست کنیم (معمولاً فرض بر عدم وجود تفاوت یا تأثیر).
- فرض جایگزین (): بیانگر حالتی است که اگر دادهها فرض صفر را رد کنند، پذیرفته میشود.
2. انتخاب آزمون آماری مناسب
بر اساس نوع دادهها و فرضیات، آزمون آماری مناسب انتخاب میشود:
- آزمون t (یک یا دو نمونه) برای مقایسه میانگینها.
- آزمون z برای مقایسه نسبتها یا دادههای بزرگ.
- آزمون کایدو (χ2) برای وابستگی بین متغیرها.
- آزمون ANOVA برای مقایسه میانگینهای چند گروه.
- محاسبه آماره آزمون (Test Statistic)
فرمول یا رابطه مربوط به آزمون انتخابی را استفاده کنید. مثلاً:
- برای آزمون t یک نمونه: t=xˉ−μsnt = \frac{\bar{x} – \mu}{\frac{s}{\sqrt{n}}} که در آن:
- : میانگین نمونه.
- μ: میانگین جامعه تحت فرض صفر.
- s: انحراف معیار نمونه.
- n: حجم نمونه.
4. محاسبه P-value از آماره آزمون
پس از محاسبه مقدار آماره آزمون، -value به صورت زیر محاسبه میشود:
- از جداول آماری: برای آزمون مربوطه (t، z، کایدو و غیره) مقدار -value را پیدا کنید.
- از نرمافزارها یا ابزارهای آماری: مانند Excel، Python، SPSS، R، یا Minitab که -value را به صورت خودکار محاسبه میکنند.
5. تفسیر P-value
-value محاسبه شده را با سطح معناداری (α) مقایسه کنید تا تصمیمگیری شود که آیا فرض صفر را رد کنیم یا نه.
مثال ساده
فرض کنید میخواهید بررسی کنید که آیا میانگین وزن یک گروه خاص 70 کیلوگرم است. دادهها به شرح زیر است:
- میانگین نمونه (x) = 72
- انحراف معیار (ss= 5
- تعداد نمونه () = 30
- فرض صفر: میانگین وزن برابر 70 است (H0:μ=70H_0: \mu = 70).
محاسبه آماره t:
t=xˉ−μsn=72−70530≈2.19t = \frac{\bar{x} – \mu}{\frac{s}{\sqrt{n}}} = \frac{72 – 70}{\frac{5}{\sqrt{30}}} \approx 2.19
محاسبه PP-value:
- با استفاده از جدول t یا نرمافزار: P-value حدود 0.036 است.
- چون -value < ، فرض صفر رد میشود.
ابزارهای رایج برای محاسبه PP-value
- Excel:
- برای آزمون t:
‘=T.DIST.2T(2.19,29)‘`=T.DIST.2T(2.19, 29)` - برای آزمون z:
‘=NORM.S.DIST(z,TRUE)‘`=NORM.S.DIST(z, TRUE)`
- برای آزمون t:
- Python (کتابخانه
scipy):
این ابزارها محاسبه را بسیار سادهتر میکنند!
وقتی از آماره آزمون test statisticو مقادیر بحرانی critical valuesبرای قبول یا رد فرض صفر استفاده می کنیم، چه نیازی به محاسبه p-value می باشد؟
استفاده از آماره آزمون و مقادیر بحرانی برای تصمیمگیری درباره فرض صفر کافی است. اما P-value مزایای بیشتری دارد که در زیر توضیح میدهم:
تفاوتهای اصلی و نقش P-value
- مقادیر بحرانی (Critical Values):
- شما قبل از آزمون، سطح معناداری (α) را تعیین میکنید (مثلاً 0.05).
- سپس آماره آزمون را محاسبه کرده و با مقدار بحرانی مقایسه میکنید.
- اگر آماره آزمون از مقدار بحرانی بیشتر باشد (برای آزمون یکطرفه) یا خارج از بازه بحرانی باشد (برای آزمون دوطرفه)، فرض صفر رد میشود.
- P-value:
- نشان میدهد که اگر فرض صفر درست باشد، احتمال وقوع مقدار آماره آزمون محاسبهشده یا مقداری شدیدتر از آن چقدر است.
- به جای مقایسه با یک مقدار بحرانی ثابت، به شما اطلاعات دقیقتری درباره شدت شواهد علیه فرض صفر میدهد.
مزایای استفاده از P-value در کنار مقادیر بحرانی
- انعطافپذیری در سطوح معناداری
با مقادیر بحرانی، تصمیمگیری فقط برای یک سطح از α (مثلاً 0.05) انجام میشود. اما با P-value:
- میتوانید برای هر سطح معناداری، تصمیم بگیرید (مثلاً 0.01، 0.10، و غیره).
- نیازی به محاسبه مقدار بحرانی جداگانه برای هر α ندارید.
- اطلاعات دقیقتر درباره شدت شواهد
- مقادیر بحرانی فقط نشان میدهند که فرض صفر رد میشود یا نه.
- اما P-value شدت شواهد علیه فرض صفر را مشخص میکند:
- مقدار کوچکتر P-value (<0.01) نشاندهنده شواهد قویتر علیه فرض صفر است.
- مقدار نزدیک به α شواهد ضعیفتری را نشان میدهد.
- تفسیر آسانتر در مقالات و گزارشها
در گزارشهای علمی و صنعتی، ذکر P-value بیشتر مرسوم است، زیرا به خواننده امکان میدهد خودش تصمیم بگیرد که بر اساس سطح معناداری دلخواه چه نتیجهای بگیرد.
- قابل استفاده در روشهای چندگانه آزمون (Multiple Testing)
در تحلیلهایی با چندین آزمون آماری (مانند مقایسه چند گروه)، P-value به شما کمک میکند که خطاهای آماری (مانند خطای نوع اول) را کنترل کنید.
تفاوتهای اصلی
| ویژگی | -Value | مقدار بحرانی (Critical Value) |
|---|---|---|
| تعریف | احتمال مشاهده آماره آزمون یا مقدار افراطیتر. | مرزی ثابت برای تصمیمگیری بر اساس α. |
| روش محاسبه | از آماره آزمون و توزیع آن. | از α و جدول توزیع مربوطه. |
| کاربرد | اندازه شدت شواهد علیه فرض صفر را میدهد. | برای تصمیمگیری مستقیم درباره رد یا قبول . |
| انعطافپذیری | برای هر سطح α قابل استفاده است. | فقط برای سطح از پیش تعیینشده α. |
آیا همیشه به P-value نیاز داریم؟
اگر آزمون را صرفاً برای یک سطح خاص از α انجام میدهید و فقط تصمیمگیری (رد یا عدم رد) اهمیت دارد، استفاده از مقادیر بحرانی کافی است.
اما در موارد زیر، P-value مفیدتر است:
- وقتی بخواهید شدت شواهد را بررسی کنید.
- وقتی بخواهید تصمیمگیری را برای چندین سطح از α انجام دهید.
- در گزارشها و مستندات، برای شفافیت بیشتر نتایج.
کد نمونه برای محاسبه P-Value با Python (کتابخانه SciPy)
python
این کد -value آزمون دوطرفه را بر اساس t و df = 29محاسبه میکند.
نتیجه گیری
استفاده از مقادیر بحرانی برای تصمیمگیری سریع و ساده کافی است، اما P-value اطلاعات عمیقتر و انعطافپذیری بیشتری فراهم میکند و در تحقیقات علمی و گزارشهای حرفهای بسیار کاربردیتر است.
دیدگاهتان را بنویسید